FindingPheno is creating an integrated computational framework for hologenomic big data, providing the tools to better understand how host-microbiome interactions can affect growth and other outcomes.
FindingPheno is creating an integrated computational framework for hologenomic big data, providing the tools to better understand how host-microbiome interactions can affect growth and other outcomes.
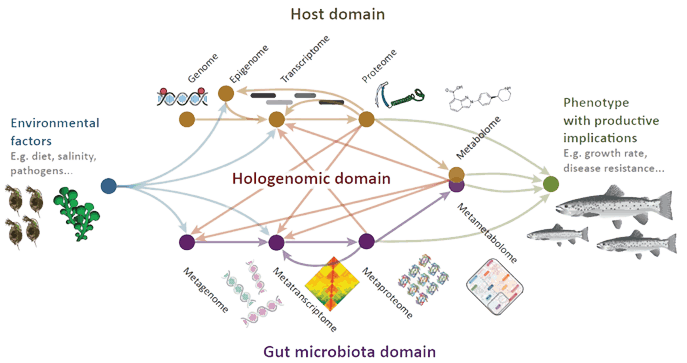
Understanding the hologenomic domain is a fiendishly difficult problem, with a complex tangle of interactions at many molecular levels both within and between organisms. FindingPheno aims to solve this problem, developing a unified statistical framework for the intelligent integration of multi-omic data from both host and microbiome to understand biological outcomes.
Partners apply state-of-the-art mathematical and machine learning approaches taken from evolutionary genomics, collective behaviour analysis, ecosystem dynamics, statistical modelling, and applied agricultural research to give a truly interdisciplinary perspective towards solving this difficult problem. The project takes a unique two-pronged approach: combining biology-agnostic machine learning methods with biology-informed hierarchical modelling to increase the power and adaptability of our predictive tools.
The tools created in FindingPheno are expected to significantly improve understanding and utilization of the functions provided by microbiomes in combating human diseases as well as ways to produce sustainable food for future generations.
Methods will be developed that go beyond the current paradigm of “pairwise” associations studies by using machine learning, Bayesian statistics and causal models to determine the structure hidden in large multi-omics data sets.
Researchers will account for the true dynamic nature of the host-microbiome system by modelling both temporal and spatial changes in the microbiome and its interaction with the host environment.
New hierarchical models will be developed to incorporate external information from existing databases and research studies, such as gene or pathway information, previous association studies, and the known evolutionary consequences of genomic and metagenomic changes.